
AI for Research: A Practical Guide for Analysts
The pragmatists guide to using AI for analysis, tailored for biotech. All for < 40$/month

So Claude 3.7 Sonnet, a new LLM model was released recently and almost immediately people were amazed. Look at it code Minecraft in one go. A new racing app in the browser! Wow, this is immediately applicable to solve my dream of coding a new gaming app.

WTF am I supposed to do with a Snake app in my browser?
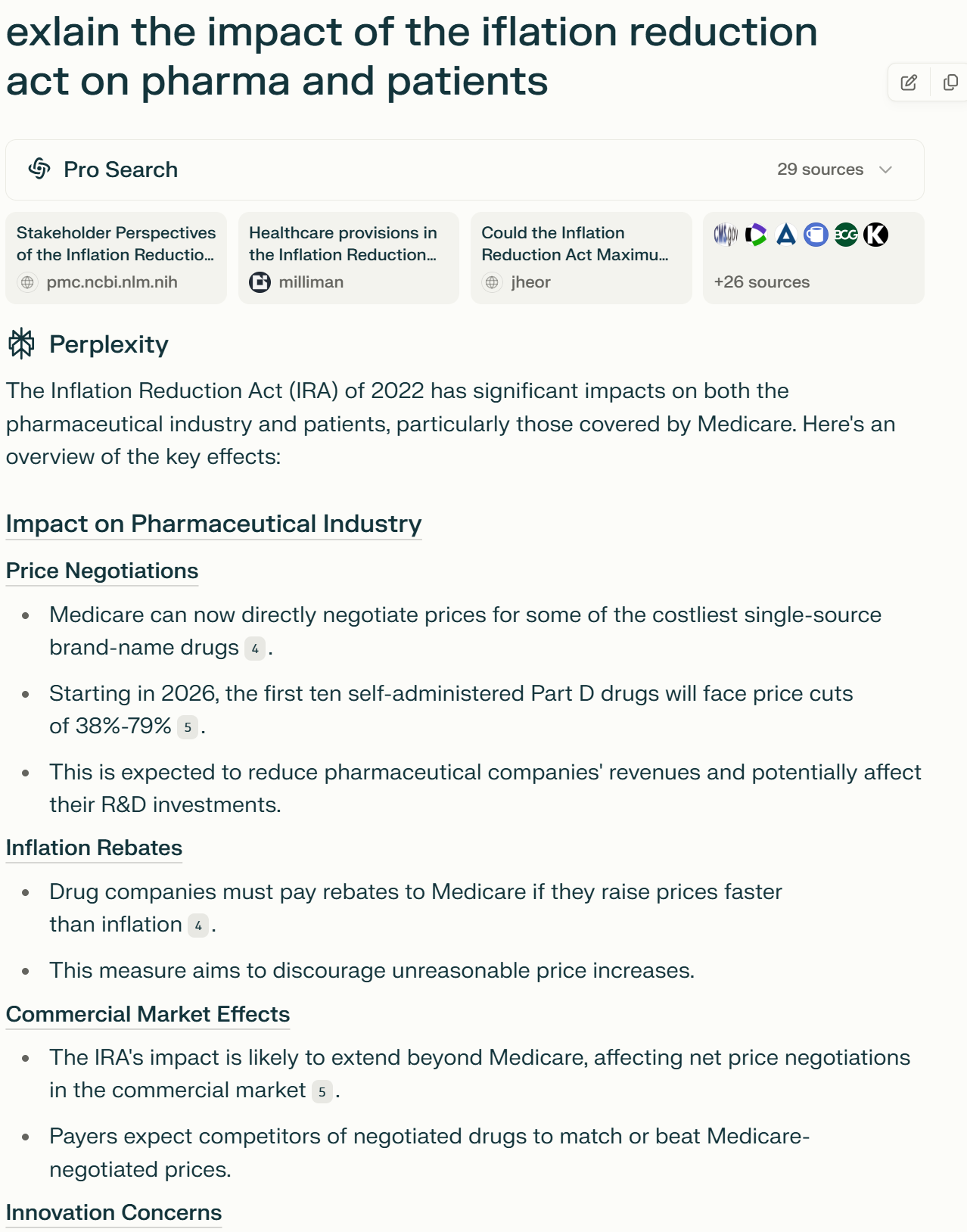
AI's promise to reshape knowledge work is real, but there’s little practical advice for analysts. Most writing consists of existential handwringing about Artificial General Intelligence (AGI), naysayers picking holes in the tools, or VCs proclaiming the next big AI agent. Most advanced tools are expensive, not ideal for individuals operating on a limited budget, but the cost of intelligence is reducing dramatically. Today, we can leverage cutting-edge tools for just $20/month that rival capabilities previously reserved for enterprise solutions.
Toolkit
Before we start: Invest $20/month in one of the frontier models (Claude, Gemini, ChatGPT). The difference in usage and capabilities is stunning.
Here are the key AI tools I leverage for analysis:
ChatGPT Plus ($20/month): My daily workhorse. I use it to summarize dense paragraphs, reformat my writing, program in Python, etc. The O1 model is excellent as a discussion partner. Deep research is Okay
Perplexity ($20 for Pro/Free): Pro search can find niche sources to pick through. Using the internet also provides a fantastic resource to create timelines and explain historical events.
Claude ($20 for Pro/Free): Great for data analysis, sentiment analysis on documents. Also excellent at programming. Free tier is rate limited.
Google AI Studio (free): A free way to access Google's advanced models. Best for instruction following. Can be used for writing.
Notebook LM (free): Upload and parse long PDFs. Interrogate multiple 100-page documents with answers sourced to the exact line.
DeepSeek (Free): Often rate limited, but the best writing assistant to discuss your own content.
Grok3 (Free): xAI's newest model. It's adequate, no special use case, but I can directly paste tweets into it.
So let’s get into it
Summary:
Use cases
Analysis of Long Form, Text-Based Documents (NotebookLM)
Go from 0 to 1 (Quick knowledge building with ChatGPT/Perplexity)
Finding Niche Sources - Forums, Blogs, etc (Using Perplexity for specialized information)
Understanding Timelines (Creating historical contexts)
Data Conversion/Extraction (Extracting clinical data from documents)
How to Write Better and Have Discussions (Using AI for writing and critical thinking)
Compare Transcripts and Press Releases (Earnings call analysis)
Tacit Knowledge and KOL Calls (Gathering clinical practice insights)
Walk Me Through That Process (Understanding clinical endpoints/methodologies)
Annual Report Analysis (SEC filing comparison)
Deep Research (Comprehensive research tools)
Pitfalls +predictions
Warnings: Sometimes Effort is the Point (The value of manual analysis)
AI Gaslighting and Human Bias (Confirmation bias and information regurgitation)
The Future of AI (Predictions about AI's impact on knowledge work)
Analysis of long form, text based, Documents.
Preferred Tool: NotebookLM - Free
Capabilities: Summarization with source citations, timeline generation, podcast-style overviews. The podcast overviews are great for easy consumption.
Guide to Using: Download FDA briefing documents, clinical trial transcripts, or academic reviews. Upload to NotebookLM (PDFs, text files, or copy-paste). Query with precision:
“Extract all safety concerns flagged by the FDA in Section 5.2 of this review.”
“Generate a timeline of key regulatory interactions for [Drug X].”
“Create a podcast script explaining the FDA’s stance on surrogate endpoints in this document.”
The FDA releases hundreds of pages with multiple reviews for each approved drug. NotebookLM can provide an introduction to key issues without brute force reading all of it. I suggest downloading the files and putting them into a notebook and asking for 1) a timeline of events. 2) a podcast prompting it to explain in depth technical details. Let’s Look at a real example:


We can download these documents and summarize them using NotebookLM.
Case Study:
The FDA’s 200-page review of tafamidis (ATTR-CM) is confusing but NotebookLM identified the exact section where reviewers debated mortality benefit inclusion in labeling. The section’s language supported my thesis on a new drug, Acoramidis. I can see a summary of meeting minutes and the medical review in seconds and generate a podcast based overview summary.
For the uninitiated, the podcast overviews are a great introduction. I can consume academic literature, dry government documents and 100 page long reports interactively and while on the go.If I need to dive deeper, I read the source documents. NotebookLM bypasses Ctrl+F hell. The podcasts are amazing as well - Audio formats force AI to prioritize narrative coherence for easy understanding.
Go from 0 to 1 on a topic
Preferred Tools: ChatGPT, Perplexity
Capabilities: Instant primers on diseases, mechanisms, or competitive landscapes.
Guide to Using:
Start Broad: “Explain the pathogenesis of vitiligo to a high school student.”
Explain from multiple perspectives: “Do a customer walkthrough from the perspective of X”
Pressure-Test: “What would a dermatologist criticize about this explanation?”
Any new topic goes directly into ChatGPT for an introduction.
Example: I want to understand the pathogenesis of vitiligo but don’t know anything about the disease. I will ask ChatGPT to explain the concept. Often I will ask it to ‘Explain like I am in high school’ and scale up from there. The tactic is no substitute for reading scientific publications, but it makes learning more efficient.
Standard of care in vitiligo ChatGPT and perplexity. An expert dermatologist would nitpick the results, but the search is a perfect introduction to the topic and can replace an introductory call with a doctor. (usually $500+)
The strategy is applicable beyond just biotech: any well studied industry is easily explained. We can combine with our own documents to further augment explanations.
Finding Niche Sources - Blogs, Forums, etc
Preferred Tool: Perplexity - aggregating the million forum links, reddit threads, and blog posts.
Guide to Using:
Google - Best for finding specific primary sources
“site:reddit .com r/biotech posts about CRISPR delivery vectors.” - targeted to a specific sources, requires processing each one
Perplexity - Best for synthesizing consensus
“What are unmet needs in myasthenia gravis? Cite patient forums and MD blogs.” - Summarizing multiple to find the right one.
Case Study: Myasthenia gravis unmet needs
When researching myasthenia gravis, a disease with multiple treatment classes and rapidly evolving standard of care, I needed to understand unmet needs for new therapies. Instead of parsing dozens of sources manually, I used Perplexity to generate a synthesis.

The surface level analysis is a good starting point to analyze the treatment landscape. Some patients may value lower treatment burden over better efficacy. Or comorbidities affect treatment selection. Or insurance coverage limits access. Previously, these insights required parsing multiple sources or expensive KOL calls. However, I must emphasize: this approach is merely a starting point. Many online sources do not reflect clinical reality, and all claims must be verified through additional research
Understand Timeline
Best GPT: Perplexity (access to the web)
Capabilities: Compressing years of regulatory/clinical history into chronologies.
Guide to Using - Prompt Template: “Timeline of [Drug/Company] including clinical holds, approvals, and competitor events.”
Understanding history provides a lens to the future. One of my favorite hacks is to ask for a timeline of any company/drug/event. Sources are often indexed by date; the LLM provides a succinct timeline. Example with Biogen and Aduhelm: link.



Case Study 2: Competitive Landscape in Sickle Cell Disease
When researching pociredir (a new sickle cell disease therapy with prior clinical holds). The standard of care for Sickle cell has changed with drugs approved and others pulled from the market. The timeline was unclear so I asked perplexity the following: “Provide a timeline of the following events: Pociredir clinical hold, Adakveo approval, Adakveo withdrawal, Oxbryta approval, Oxbryta withdrawal”
And voila, a perfect timeline of events appears.

Data conversion/extraction
Preferred Tools: Google Gemini and Claude
Cost: Free (using AI Studio)
Guide:
Upload a clinical trial PDF or screenshot containing data tables
Prompt the AI with specific instructions: "Extract the efficacy data table from page 4 into a CSV format"
Copy the structured output into your spreadsheet for analysis. Verify accuracy and clean up any misinterpretations
I spend countless hours inputting clinical data into Excel for cross-trial comparisons. What used to be a mind-numbing exercise in data entry is now pretty easy. The accuracy isn't perfect, but at a 90% success rate with minimal cleanup, the ROI is undeniable. Some people like inputting numbers one by one, but has that really led to any deep insight? I still have to read the paper, but the data extraction piece is automatable.
Note: Data extraction works best for tables. Graphs are hard to parse and any LLM has a difficult time understanding the mechanics of time. (i.e. Quick response vs fast response). Units should be precise too.
Data Extraction - 1740515634951.mp4
How to write better and have discussions
Preferred Tools: DeepSeek R1 (primary), Gemini (alternative), Claude 3.7 (good for nuanced writing)
Capabilities: Writing assistance, thought organization, critical feedback, and counterargument generation
I recoil at the thought of an internet filled with unreviewed AI "slop" (Twitter already offers a dystopian preview), but the right collaboration with AI drastically improves my writing.
Helpful Prompts:
“I think X is true: tell me why I am wrong” - Upload documents for better context.
"You are a skeptical biotech investor. Question my investment thesis on [Company X]." AI: *proceeds to poke holes in your logic that you hadn't considered*
"Simplify this technical explanation for an educated non-specialist"
"Reorganize my draft to improve logical flow while preserving my key points"
Communication is the lifeblood of analysis, and LLMs excel at transforming my scattered thoughts into coherent documents. More importantly, they create a space for intellectual exploration:
I prompt the AI to consider my analyses and ask for refuting opinions. The AI doesn’t capture up to date information but reveals patterns in my thought process and forces clarity of thought.
Compare Transcripts and Press Releases
Capabilities: Detecting subtle shifts in management guidance, tone, and strategic focus
Every quarter, thousands of companies report results and host conference calls. Traditional analysts offer competing interpretations that are largely commoditized. Rather than relying solely on external opinions (Twitter, sell-side reports), I’ve started to emulate the role of a junior analyst. If I see something interesting, I will look deeper.
The approach is simple:
Input the current and previous quarterly transcripts/earnings releases
Prompt: "Compare these transcripts and identify major changes in management commentary about [specific areas of interest]. Focus particularly on [key metrics/initiatives]."
Ask to organize by program or topic of interest with old value, new value, and a description
I've implemented this in a tool that tracks commentary changes over time at www.subradata.com/transcript_updates and www.subradata.com/daily_changes.
Real-world applications:
Tracking FDA interactions: For Fulcrum Therapeutics, this approach highlighted subtle shifts in regulatory discussions.

Monitoring catalyst timelines: For BridgeBio, comparing Q3 and Q4 transcripts revealed changes in anticipated milestone dates.

More in depth analysis: For CVRX, I used "Compare the two transcripts and identify major changes in management commentary on future events, timelines, revenue. Focus on changes to Medicare reimbursement, selling and marketing changes" and received a more in depth report comparing Q3 and Q4.
Tacit Knowledge and KOL calls - Specifically in healthcare
Specifically in healthcare: A Key opinion leader is an expert in a specific field, disease, or prior company employee. Talking to a Key Opinion Leader (KOL) can capture the unwritten rules of clinical practice: what doctors actually do versus what guidelines suggest they should do. This tacit knowledge gives outsiders a deeper understanding. But these calls are expensive, time-constrained, and often surface level.
Perplexity, and other search tools function as aggregators of collective clinical experience. It can surface conversations from physician forums, patient communities, and clinical discussions where practitioners share their real-world approaches.
Example: When researching Hereditary Angioedema (HAE) before KalVista's Sebetralstat approval, one critical question was: "What percentage of patients on prophylaxis still carry an on-demand option?"
A well-crafted Perplexity search revealed threads from physician discussions indicating that nearly all patients maintain on-demand options as safety nets, even when on effective prophylaxis. The AI initially overstated this as "100% of patients," but the directional insight was valuable enough to reshape my line of questioning for subsequent expert conversations. Note: the estimated % is in line with the KOL calls performed by TD - Cowen.

What % of your prophylaxis-treated HAE patients are also prescribed on-demand…

I would use this introduction to dig a little deeper.
“Walk me through that process”
Tools: any LLM works. Perplexity with search can be helpful.
Goals: Understanding the methodologies and limitations behind clinical measurements Prompt LLMs to explain measurement methodologies step-by-step. Use Perplexity to investigate biases and assessment heuristics.
Clinical endpoints appear as clean numbers in presentation slides, but the reality involves human variability and methodological nuance. I maintain a spreadsheet tracking endpoints and their associated assessment heuristics across therapeutic areas, built using LLMs to locate relevant explanations and source materials. I'm accelerating the "feel" analysts develop over time.
Effective Prompts:
"Explain how [specific measurement] is assessed in clinical practice"
"What are the known limitations and variability issues with [endpoint]?"
"How do different clinical sites typically calibrate [measurement] to ensure consistency?"
Example:
Consider the North Star Ambulatory Assessment (NSAA) used in Duchenne Muscular Dystrophy (DMD) trials. Sarepta released “positive” long term results in January 2025 and investors were mixed.
The therapy received accelerated approval on limited evidence
Efficacy signals remained inconsistent across measures
The NSAA endpoint itself exhibits significant variability
Perplexity explained the typical improvement until age 7, plateau until 9, and decline thereafter. The heuristic contextualizes the data. Further, I use GOOGLE (Yes, the one meant for *dinosaurs* it seems) to locate a real life NSAA explaining the specific activities measured. This approach transforms abstract endpoint discussions into concrete understanding of what's being measured in the clinic.
Longitudinal Report analysis
Tools: NotebookLM, ChatGPT, Claude Projects are ideal.
Cost: Varies, 20$/month
Effective approaches:
Year-over-year comparison: "Compare the Risk Factors sections from the 2023 and 2024 10-Ks. Highlight new risks, removed risks, and changes in emphasis."
Management tone analysis: "Analyze the tone and confidence level in the MD&A sections across the last four quarterly reports. Has management's language about [specific initiative] changed?"
Disclosure patterns: "Identify any recurring patterns in how the company discloses [specific metric] and how it has evolved."
We can see Brett Caughran analyze Humana’s annual reports here: The Cutting Edge Webinar Series — Fundamental Edge. Most modern LLMs can now process entire SEC filings, enabling targeted analysis that would take hours manually. Rather than scanning for changes yourself, upload sequential filings and ask specific comparative questions. As models improve, our ability to extract insights from dense financial documents will only get better.
Deep Research
Leading Products: OpenAI Research, Google AI Studio, Perplexity Deep Research
Cost: $20-200/month (varies by provider)
Capabilities: Comprehensive web research, multi-source synthesis, formatted reports
OpenAI, Google, and Perplexity have all launched "deep research" products with distinct approaches:
OpenAI Deep research: Iteratively searches the web, evaluates document relevance, validates information, and produces comprehensive reports. recently available to $20/month tier. Pretty good
Google Deep Research: Focuses on broad information synthesis from multiple sources. Good
Perplexity Deep Research: Functions more as an advanced search tool with limited reasoning capabilities compared to the others. Okay.
Some users highlight quality on par with professionals. All paid users can access 10 queries per month. However, each one suffers from a core issue: I have to verify all the information. A 60 page report is great……until I have to read it all to understand my query. Deep research produces a “crappy sell-side initiation report” so why would I read it at all. Still, people are still paid for those research reports. Deep Research is probably the closest to “replacing white collar work” for any tool, but it’s a very specific use case.
The key is having a process. When researching a new space, what questions do you ask? Why? Define that upfront, and the LLM will follow. Finding answers is easy. Asking the right questions is the hard part.
Limitation: Deep research tools don’t work on paywalled content. That’s a problem, especially in academia, where locked-up research slows progress. OpenAI might solve this eventually. For now, people get around it by uploading full documents and letting AI summarize them.

How to stay updated with limited time.
The AI world moves too fast. New breakthroughs, endless hype, and conflicting takes make it impossible to track. “ChatGPT is coming for your job.” Then: “It hallucinates too much.” Then: “Forget that, it’s all about agents.” It’s exhausting.
If you don’t have unlimited time (who does?), a simple system works to stay up to date:
Read the Free articles from Stratechery and Ben Evans: they will track important updates and the philosophy of AI.
Read Ethan Mollick’s substack for helpful tips and new updates.
Once a month,skim OpenAI, Anthropic, and Google articles/releases. See if anything matters.
Podcasts/Webinars: Follow Dwarkesh’s podcast, Invest Like the Best, Lex Fridman for some interesting guests such as Modest proposal, Satya Nadella, and Stephen Wolfram, For investors, pay attention to Brett Caughran's FundamentalEdge Cutting Edge webinars

Warnings: Sometimes effort is the point
Sometimes, effort is the point. Research is driven by data and as I’ve outlined in the post, AI accelerates our ability to process information. However, while AI replaces rote tasks like data summarization and synthesis, handing your mental effort to AI asks too much. Further, the "elbow grease" involved in collecting and synthesizing information forces a level of engagement. Work builds the mental models we rely on for expert judgment.. Ben Thompson put it well
“ There is so much you learn on the way to a destination, and I value that learning; will serendipity be an unwelcome casualty to reports on demand? Moreover, what of those who haven’t — to take the above example — been reading Apple earnings reports for 12 years, or thinking and reading about technology for three decades? What will be lost for the next generation of analysts?”
For developing analysts, there remains significant value in occasionally doing things the hard way—manually inputting those numbers, working directly with primary sources, and building analytical frameworks from scratch
AI Gaslighting and Human Bias
Ask an LLM for an opinion, and it will generally agree with you. AI is trained on a massive corpus of human-generated text, a significant portion of which reflects existing biases. It's challenging to create an AI that dissents and offers counterintuitive insights.
AI is still yet to produce a single novel insight in my experience. Rather, AI has revealed the power of collective intelligence: humans have discovered much more than has been implemented and we can now process all the information out there to find those insights.
However, if you ask for an opinion, AI will generally agree with you. This is a ****vibes****based observation, but creating disagreeable AI crafting novel insights is difficult.


People will gaslight you
Even when attempting to source analysis to primary documents, the risk of bias remains. Management teams, scientists, even seemingly objective bloggers – all are subject to inherent biases. So if they gaslight the tool, the tool will gaslight you.
I input transcripts from last September into a model and asked about the impact of data presented at ESC. Here are the conclusions. Prompt: Tell me if the data presented at ESC was positive for Bridge Bio or Alnylam. Tool: AI Studio. So it comes to a conclusion, but the conclusion may not be right. It’s simply a regurgitation of what it’s read.

We see this pattern repeatedly when uploading documents and asking for forecasts or comparative analyses: AI simply summarizes the available information.
Skepticism is highly valued for investment professionals and AI isn’t there.

The Future of AI
AI models will continue to improve and the nature of knowledge will be transformed. I genuinely think the nature of white collar knowledge work is at risk. "White collar scut work" – those routine tasks performed by junior developers, lawyers, investment banking associates, and consultants – are most at risk. But your jobs are safe….for now. Paywalls, litigation, and regulation are the wet tarp to unbridled AI optimism. Plus no one wants AI-generated “slop”.
I’m not an expert. I’m merely a tinkerer. And my relentless tinkering brings me to a few conclusions on the future of AI
Curated Data is the most valuable resource. Humans have collectively discovered a lot but processing the information we produce is intractable. Curating valuable data can lead to faster insights
AI cannot replicate credibility. Mckinsey isn’t paid for insight: they’re paid for a brand.
Real world problems will become the bottleneck. Problems where information was the rate limiting step will be accelerated while real world interactions will become the real issue
Tech enabled services are the best way to win in a post AI-world. The ideal use case is easy to evaluate the outcome with a structured process. Forecasting requires much more thought.
I have more thoughts and ideas on a few companies, but I’ll leave it there before the tangent rambles on.
Conclusion and Appendix
We’ve explored how to use AI in your research process and some of the drawbacks. Furthermore, we’ve done it for < 50$ a month. I firmly believe AI is here to revolutionize knowledge work but we will need a mix of human and machine for true insight. AI will perform tasks but we can get an edge by exploring at the frontier. I hope this guide inspires you to experiment with these tools in your own workflow
If you enjoy my writing: check out www.subradata.com. I’m helping smart investors compete by offering low cost tools using AI like AI transcript comparisons, earnings release comparisons, and
If you have questions or thoughts: comment below, contact me at adu.subramanian@subradata.com, or shoot me a tweet at @plainyogurt21
Excellent article, thank you!